Esta es la primera entrada de una serie de entradas que quiero escribir en relación a diversos soluciones o patrones de los cuales siempre he tenido un conocimiento teórico, y que hay veces en los que no he tenido la oportunidad de ponerlos en marcha empezado por los mecanimos para realizar cacheado de request.
Desde un punto de vista teórico, entiendo que me servirá para afianzar conocimientos sobre dichas áreas. Además que tengo la esperanza de que en algunos de estos ejemplos prácticos, ser capaz de ilustar la diferencias entre distintos mecanismos y de verdad corroborar los escenarios en que dichos patrones o soluciones son adecuados.
Tal y como he comentado anteriormente voy a comenzar con soluciones para el cacheado de requests. En general, cuando se intenta acceder a una REST API, si hay una operación que no tenga ningún tipo de efecto colateral y que sea idempotente, es un buen candidato para que las respuestas de esas peticiones sean cacheadas y que no sea necesario acceder a dicho recurso en el servicio porque esa información ya se obtuvo en una petición anterior. Dentro del las operaciones que se definen para una REST API que pudiera ser cacheable sería la operacion GET siempre que esta no tuviera ningún efecto lateral (que estuviera implementada tal y como dice la especificación sin modificar nada) y que fuera idempotente (hay ocasiones en que la operación no es idempotente, por ejemplo, cuando de alguna manera se lleva un contador de cuantas veces ha sido ejecutada dicha operación).
Para este ejemplo, he asumido que la operación va a ser un GET el cual se presupone que cumple las condiciones anteriormente indicadas.
Todos los mecanismos que conozco para poder llevar el control de dicho cacheado a nivel de REST API, están basados en headers que se devuelve como parte de la respuesta y en función de dicha información actuar en consecuencia.
Los headers que conozco para dicho control del cacheado de request son:
- Expires
- Cache Control
- eTag
- Last Modified
Cada uno tiene un uso distinto y un lugar distinto en el cual poder realizar dicho cacheado. Con este conjunto de cabeceras hay dos formas de interpretar el cacheado de request:
- Tenemos un agente intermedio entre el llamante y la REST API (un proxy) el cual es capaz de hacer uso de esas cabeceras de retorno para determinar si es necesario volver a ir a la REST API cuando se realiza una segunda request
- Ofrecer la posibilidad al llamante a identificar que en una segunda petición al mismo servicio nada ha cambiado. Por ejemplo, un sistema que muestre los datos de una persona, y después de cada operación en la aplicación refresque dicha vista, puede realizar la petición e identificar que no ha cambiado nada y no tener que realizar cambios de estados internos.
Para ser capaz de tener un sistema local donde se puedan simular estos escenarios, he preparado un repositorio en https://github.com/chintoz/solution-cache-request-mechanism en el cual se muestra el comportamiento de dichas caberas. Para ello se ha montado con docker-compose una aplicación con unas capas de la siguiente manera:
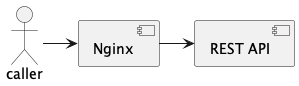
Y por ejemplo para la primera interpretación del cacheado de request, se esperaría un comportamiento como el que sigue:
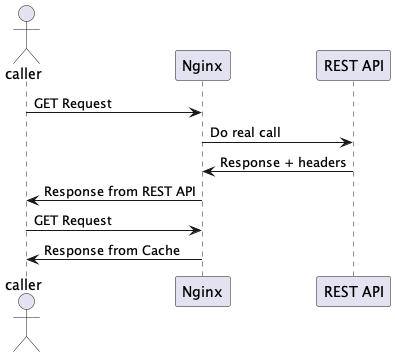
En el README del proyecto se indica como lanzar el proyecto y los endpoints existentes para demostrar cada uno de los casos.
Cacheado desde el punto de vista del servidor
Los mecanismos basados en las cabeceras Expires y Cache Control, permiten un control desde el lado del servidor para identificar si tiene que volver a realizar la petición o no.
En este caso, sería NGINX el encargado de utilizar estas cabeceras para identificar si la request realizada con anterioridad, y de la cual ha guardado su resultado, si es necesario volverla a realizar o no.
La principal diferencia entre ambas caberas es la infornación que llevan:
- Expires lo que tiene es una fecha de cuando el recurso expira: Sat, 02 Sep 2023 22:46:38 GMT
- Cache Control proporciona información del tiempo de validez de esa respuesta: max-age=86400 (existen más valores que se configuran a nivel de Cache Control como si se debe realizar cacheado de request o no …)
En el ejemplo que se muestra en el código, los endpoints bajos los paths /cached/expires y /cached/cacheControl, tienen un retardo en la respuesta de unos 10 segundos. De esta forma podemos ver que la primera invocación pasa por todas las capas y llega hasta la API la cual tarda en darnos la respuesta 10 segundos, pero las siguientes peticiones, son servidas directamente por la caché que se encuentre en la capa del NGINX, de forma que las sirve inmediatamente.
En la siguiente imagen se muestra como las primeras peticiones toman 10 segundos y las segundas apenas las sirve el NGINX:

Este es un ejemplo de uso de estas cabeceras cuando al recurso al que queremos acceder tiene un impacto negativo en el rendimiento, ya que es un recurso bastante “pesado” de obtener.
Cacheado desde el punto de vista del cliente
Las otras dos cabeceras que se pueden hacer uso desde un punto de vista del cliente son eTag y Last Modified.
Con estas cabeceras podemos identificar desde el punto de vista de un cliente que hace peticiones frecuentes al mismo recurso para identificar si se han producido cambios, si en realidad se han producido o no.
Estas cabeceras nos permiten identificar que un recurso al que accedimos anteriormente, no ha sido modificado, recibiendo una respuesta 304 desde el servidor, indicando que el documento no ha sufrido cambios.
En realidad desde el punto de vista del NGINX que tenemos en frente de nuestra API, la petición se acaba realizando, porque en realidad la información que viene en estas cabeceras no son relativas a la validez de esa respuesta, sino que esta cabecera define una forma de identificar si un recurso ha sido modificado o no.
Además desde el punto de vista del llamante, el tipo de respuesta que recibe no se realiza con una respuesta del tipo 200, sino que se devuelve una respuesta del tipo 304 (sin contenido), de forma que identifica que no tiene que realizar ninguna acción al respecto.
La principal diferencia entre ambas caberas es la infornación que llevan:
- eTag lleva como información una especie de hash code del documento devuelto, de forma de que si se produce un cambio de dicho docuento el valor del hash code será distinto: 1693011640000
- Last Modified proporciona información de cuando se modificó el documento por última vez, de forma que si el resultado de la siguiente llamada obtiene el mismo valor de la marca temporal, denotará que el contenido es el mismo: Sat, 26 Aug 2023 01:00:40 GMT
En estos casos, el principal impacto en el rendimiento va a estar del lado del llamante. En el caso de tengamos un cliente que tenga que actualizar datos periódicamente y el proceso de la actualización de la interfaz gráfica sea pesado, este mecanismo puede ayudarle a reducir dicho impacto, realizando sólo dicha actualización cuando haya nuevo contenido que visualizar.
Para hace chequear estos ejemplos hay que utilizar los siguientes accesos a la API /cached/eTag y /cached/lastModified.
Conclusión
Muchas veces se consideran mejoras sobres APIs, pensando solamente desde el punto de vista de la API que podemos hacer, ya sean caches para acceder a los datos, indices, etc.. intentando que nuestra API tenga un rendimiento mejor.
En algunos escenarios, puede complicamos en demasia nuestra API cuando a veces es suficientente con realizar operaciones para evitar que nuestra API sea llamada y delegar esa responsabilidad en un API Gateway (en nuestro repositorio es el NGINX el que estaba haciendo esa función).
En ese caso existen diversas cabeceras de las cuales podemos hacer uso, y que nos proporcionan cierto control de qué información se está retornando, cuanto tiempo es válida o cuando fue la última vez que ae modificó
No todo es positivo con este tipo de soluciones. Como todos los mecanismos de cacheado de request, el problema viene cuando esos datos son modificados, y tenemos que invalidar dicha caché. En función de la frecuencia de actualización de esos datos, hay que decidir qué mecanismo es el que mejor se ajusta a nuestras necesidades.